Over the past two years, the way people find answers online has fundamentally shifted. Large language models (LLMs) like ChatGPT, Claude, Gemini, and Perplexity are no longer just productivity tools, they’re becoming decision-making engines.
In this new world, visibility isn’t about being ranked, it’s about being mentioned. Welcome to the age of GEO: Generative Engine Optimization.
But a critical question remains: Is GEO truly a new practice, or just the same old SEO with a new name?
In this study, we focus on the two dominant forces shaping the search visibility landscape: Google, the leading search engine with a 95% market share in the U.S. and Europe (State of Search Q2 2025, Datos), and ChatGPT, the leading AI chatbot, which now holds 79.33% of the AI chatbot market (Statcounter, August 2025).
While many LLMs exist, ChatGPT has become the default starting point for AI-powered queries, making it the most commercially relevant model for marketers to optimize for. That’s why, for this study, we focused on Google rankings vs ChatGPT answer mentions.
Core Question
If you follow the SEO playbook for Google, will that also help your brand appear in ChatGPT answers?
If the answer is “yes,” then maybe GEO is just a continuation of SEO. But if the answer is “no,” and brands that dominate organic search rankings are not consistently mentioned in AI answers for the same queries, then we may be looking at a fundamentally new discipline.
This study was conducted with the guidance of Omer Ben-Porat, PhD, an AI researcher. Omer is also an Assistant Professor at the Technion, though the study was conducted independently of the institution.
Hypothesis
Because traditional search engines and LLMs are built on different foundations (crawling, indexing, and link graphs vs. language patterns, semantic authority, and consensus), we hypothesize that organic dominance in Google will not fully correlate with visibility in ChatGPT.
Another reason we expected low correlation is the difference in user intent framing. Search engines rely on exact-match keywords and ranking signals tied to a specific URL, while LLMs synthesize an answer based on how the prompt is phrased and the broader context it implies. This means the same brand could dominate page-one results for a keyword in Google but remain absent in ChatGPT’s generated response if the model interprets the intent differently or favors more explanatory, generalized sources.
Methodology
To test this, we designed a structured, cross-model experiment.
Step 1: Choose Highly Competitive Organic Search Categories
To ensure we analyzed brands applying strong SEO fundamentals, we deliberately selected five high-intent, high-volume, highly competitive verticals in the U.S.:
- Car Insurance
- Credit Cards
- Hotel Booking
- Online Courses
- Web Hosting
In categories this competitive, ranking on Google’s first page is virtually impossible without robust SEO practices. By focusing on saturated verticals, we could reasonably assume that the leading brands are actively investing in SEO, creating the right baseline to test correlation with LLM visibility.
Step 2: Identify Top SEO Performers in Each Category
Using tools like Ahrefs and Semrush, we identified the top three domains in each vertical based on non-branded organic traffic from Google U.S.
Why non-branded? We deliberately filtered out branded queries to isolate competitive, generic terms, the kind SEO teams truly battle over. This choice also removed external factors like offline campaigns or paid media that can artificially inflate branded search traffic. Since our goal was to compare the influence of organic SEO on LLM visibility, it was essential to eliminate any outside signals that might distort the correlation.
| Category | Top Performer 1 | Top Performer 2 | Top Performer 3 |
|---|---|---|---|
| Car Insurance | Allstate | Liberty Mutual | Geico |
| Credit Cards | Discover | Credit Karma | Bank Of America |
| Hotel Booking | Expedia | Hotwire | Kayak |
| Online Courses | Coursera | Harvard | edX |
| Web Hosting | Godaddy | Hostinger | Namecheap |
Step 3: Build a Representative Keyword Set
For each category, we selected 200 overlapping keywords among the top-ranked brands, resulting in a dataset of 1,000 queries overall.
To keep the dataset representative, we included a mix of:
- Highly competitive and less competitive terms: to balance between head-to-head battlegrounds and easier wins.
- Short-tail and long-tail queries: covering both broad, high-volume searches and more specific, intent-driven phrases.
- Different intent types: informational, navigational, and transactional queries, reflecting the real mix of how users search.
- Keyword variations: singular vs. plural forms, phrasing differences, and synonyms, to mirror the diversity of natural search behavior.
In addition to building this keyword set, we also mapped the exact Google U.S. rankings for each term to establish the SEO baseline. Using Serphouse API, we collected results at the root-domain level, limited to the top 10 organic positions only, excluding AI Overviews, ads, local packs, and featured snippets. All queries were run in incognito mode to avoid personalization effects. For every keyword, we recorded the precise ranking position within the top 10 and noted whether the brand appeared there or not. This allowed us later to measure both the correlation between exact SERP position and ChatGPT mentions as well as the overall overlap of brand presence across the two environments.
Step 4: Converting Keywords Into LLM Queries
In Google, users typically type short, functional keywords to trigger results. In LLMs, however, people phrase their requests in full, conversational questions.
To make a fair comparison, we transformed each keyword from the previous step into a natural-language prompt that reflects how real users interact with ChatGPT.
For example:
- “best car insurance for seniors” → “What’s the best car insurance company for seniors?”
- “personal loan for bad credit” → “Which banks offer personal loans for bad credit?”
While LLMs perform internal query expansion (query fan-out), to interpret a prompt from multiple semantic angles and increase the chance of producing a comprehensive answer, this process happens behind the scenes and isn’t directly measurable. Instead of trying to replicate it, we accounted for variation earlier: by including multiple keyword types and intent-specific phrases in our dataset, we effectively built those variations into the experiment from the start.
This way, the mapping remained clean (one Google keyword = one ChatGPT prompt), while still capturing a wide range of real-world phrasing and intent. It gave us the “apples-to-apples” precision needed to measure correlation between Google rankings and ChatGPT visibility without losing the richness of diverse queries.
To deepen the analysis, we also categorized prompts into three intent groups which tested separately:
- General Exploratory: Control group where no brand mention is expected (e.g., “How does car insurance work?”).
- Feature-Based Decision: Tests whether LLMs recommend brands based on specific needs, and whether those align with SEO leaders (e.g., “Best car insurance for young drivers”).
- Brand-Seeking: Tests whether dominant SEO brands surface when users explicitly seek recommendations (e.g., “Which banks offer the best personal loan rates?”).
Step 5: Run Visibility Tests in ChatGPT
We ran our prompt analysis on the latest ChatGPT-5 model using Chatoptic’s LLM Visibility software. Unlike most visibility tools that rely on batch requests (which return less accurate results), our system sends each prompt separately, replicating a real person asking the question in real time. We broke this step into multiple controls to replicate how real users in the U.S. actually interact with ChatGPT:
1. Location Control: U.S.-Based Proxy
Since SEO rankings in this study were based on Google U.S., it was critical that the LLM queries reflect the same geographic context. All prompts were routed through a U.S.-based proxy so ChatGPT’s responses would align with location-sensitive patterns in U.S. search behavior.
2. Persona-Based Prompting
ChatGPT doesn’t just return a static answer, it adapts responses to the person asking. Two people asking the same question can often receive different answers, because the model tailors its output to the user’s context. That’s why it was essential for us to replicate not only the query but also the identity behind it, and ask each question “on behalf” of a real person.
To improve realism beyond simple query wording, Chatoptic assigns each set of prompts to a fully defined U.S. persona. These aren’t just labels like “19-year-old student” or “business traveler”, our unique technology generates a detailed identity and backstory that the model is aware of at the moment the question is asked.
For example: A prompt such as “best car insurance for young drivers” was asked through the lens of a 19-year-old student persona, including life context (e.g., limited driving experience, budget concerns).
This approach goes far beyond what other LLM visibility tools do. It simulates how real people with specific backgrounds and needs would interact with ChatGPT, making the results more accurate and commercially relevant. It’s also one of the core features that differentiates Chatoptic’s methodology in the LLM visibility field.
3. Dual Testing: With and Without Web Browsing
Each prompt was tested twice: Once with Web Browsing OFF and once with Web Browsing ON. This dual setup allowed us to measure how real-time web access changes brand visibility. Since users may interact with ChatGPT in both modes, the comparison clarified how “fresh” web content influences which brands the model recommends. In both cases, we recorded whether the top SEO-performing brands appeared in the answers.
4. Standardizing Brand Mentions via System Prompt
ChatGPT often responds with product-level suggestions, mixes sub-brands, or omits brands entirely for exploratory queries. To make results comparable, we used a lightweight system prompt instructing the model to:
- Return only brand names
- Avoid sub-brands/product lines (e.g., “Harvard” instead of “Harvard Business School Online”)
- Map subsidiaries to their parent brand unless the sub-brand is more recognizable
- Eliminate duplicates
- Format results in a consistent JSON array
This process did not affect which brands the model selected, only how the output was structured, allowing us to compare mentions consistently across hundreds of prompts.
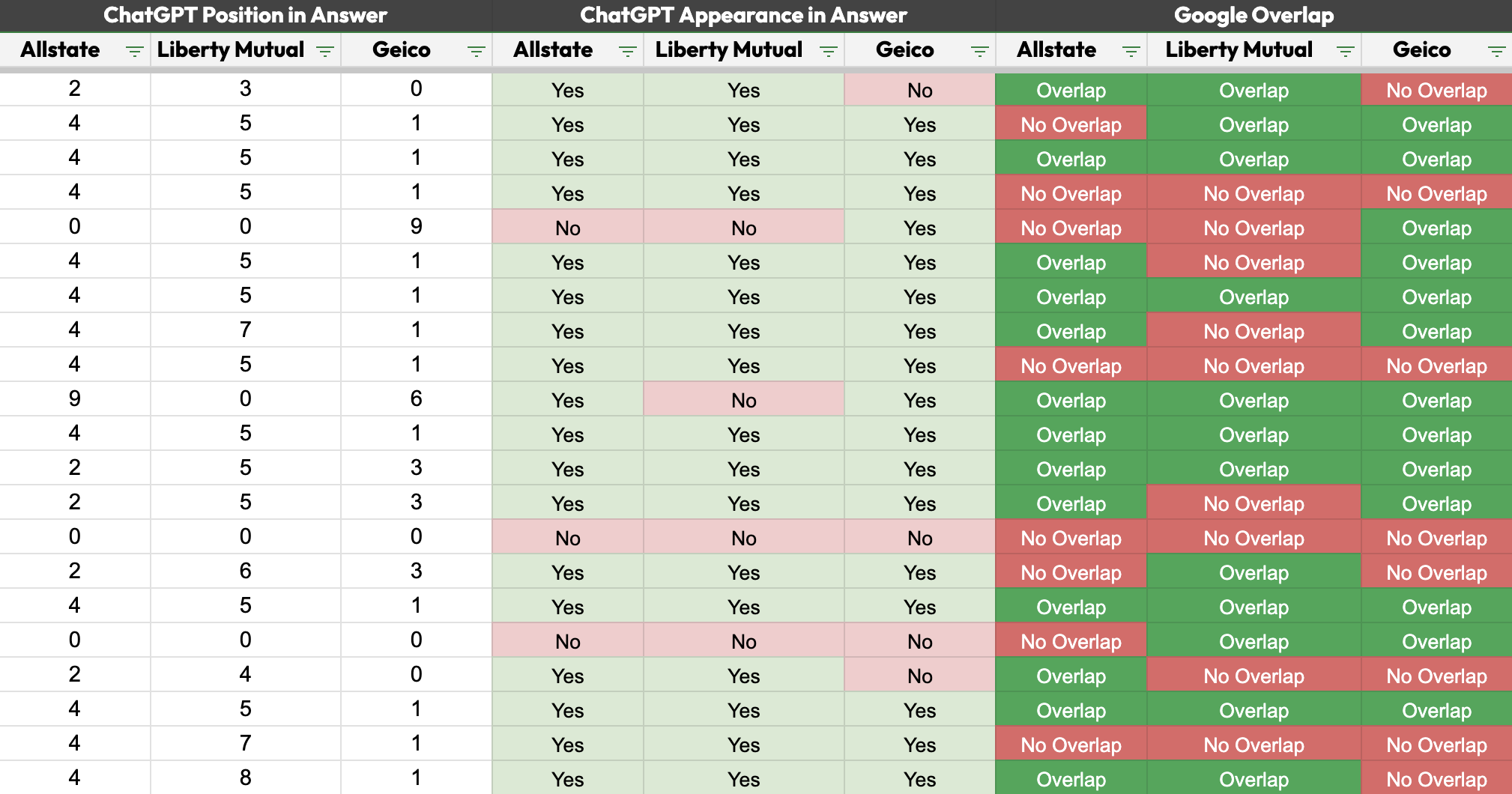
Finally, just as we did in Step 3 for Google results, we also measured the position of each brand mention within ChatGPT’s answers. For every prompt, we recorded both whether a brand was mentioned at all and where it appeared in the answer. With this, we had a complete dataset across both Google and ChatGPT, ready for the next step of analysis.
6. Analyze the Correlation
In traditional search, appearing on Google’s first page is the benchmark for SEO success. In contrast, ChatGPT delivers a single, synthesized answer, so from a user’s perspective, being mentioned in that answer serves a similar purpose.
Our analysis centered on two core comparisons:
- Presence vs. Absence (Overlap): Did Google and ChatGPT align on whether a brand appeared for a given query? (Both present, both absent = overlap; present in one but not the other = no overlap). Overlap is not a measure of brand strength on a single platform, but rather a measure of consistency between the two platforms.
- Position-to-Position Correlation: When a brand was present in both environments, did its rank order in Google (positions 1–10) align with its order of mention in ChatGPT’s list?
To make the two environments comparable at this level, we standardized ChatGPT responses to always return 10 brands per prompt using a custom system prompt. This provided a consistent dataset that mirrored the top 10 results in Google.
Finally, to ensure maximum accuracy, we examined both comparisons across four dimensions:
- Per Brand: Measuring alignment at the company level.
- Per Category: Testing whether some verticals show stronger alignment than others.
- Per Prompt Intent: Separating exploratory, feature-based, and brand-seeking queries.
- Browsing Mode (ON vs. OFF): Comparing responses with and without real-time web access.
This multi-dimensional breakdown allowed us to identify not only aggregate trends, but also whether brand identity, market category, query intent, or browsing mode meaningfully influenced consistency between Google rankings and ChatGPT mentions.
Results
1. Presence vs. Absence (Overlap)
This analysis measured whether brands that ranked on Google’s first page for a given query were also mentioned in ChatGPT answers.
By Brand
| Brand | Overlap (Web) | Overlap (No Web) |
|---|---|---|
| Allstate | 61% | 60% |
| Liberty Mutual | 58% | 61% |
| Geico | 61% | 61% |
| Discover | 71% | 70% |
| Credit Karma | 61% | 64% |
| Bank of America | 52% | 48% |
| Expedia | 60% | 64% |
| Hotwire | 53% | 52% |
| Kayak | 62% | 58% |
| Coursera | 86% | 87% |
| Harvard | 61% | 53% |
| edX | 47% | 48% |
| GoDaddy | 83% | 83% |
| Hostinger | 34% | 32% |
| Namecheap | 74% | 74% |
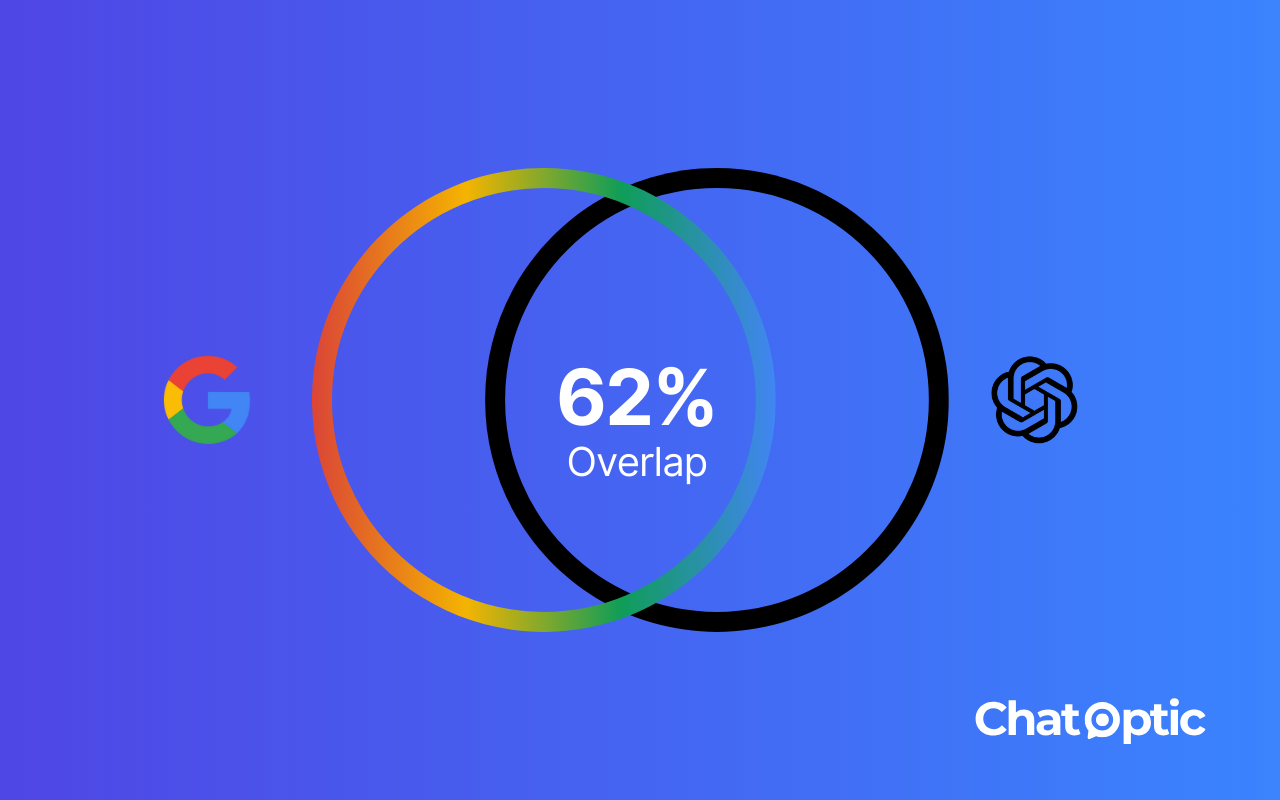
| Total Avg. | 62% | 61% |
Overlap varied significantly by brand.
- Higher overlap: Coursera (86–87%) and GoDaddy (83%) showed strong alignment between the two platforms, with their presence (or absence) matching more often than not.
- Lower overlap: Hostinger (32–34%) and edX (47–48%) displayed less alignment, with more frequent cases where they appeared in one platform but not the other.
- Mid-range overlap: In categories like car insurance, large incumbents (Progressive, Liberty Mutual, Allstate) clustered around 58–61%, reflecting moderate consistency.
Takeaway: Even within the same category, overlap rates diverge sharply. Some brands showed relatively high alignment (e.g., Coursera at 86–87%), while others showed very low alignment (e.g., Hostinger at 32–34%). Yet across all 15 brands analyzed in 5 categories, the overall overlap averaged only 61–62%, far from full consistency. This confirms that strong SEO performance in Google does not guarantee parallel visibility in ChatGPT.
By Category
| Category | Overlap (Web) | Overlap (No Web) |
|---|---|---|
| Car Insurance | 60% | 60% |
| Credit Cards | 61% | 61% |
| Hotel Booking | 58% | 58% |
| Online Courses | 65% | 62% |
| Web Hosting | 63% | 63% |
| Total Avg. | 62% | 61% |
Average overlap across categories ranged from 58% to 65%.
- Highest overlap: Online Courses (65%), reflecting a concentrated market with a few clear leaders.
- Lowest overlap: Hotel Booking (58%), a highly fragmented space with many players, leading to weaker cross-platform consistency.
- Middle ground: Car Insurance (60%) and Credit Cards (61%) fell close to the overall average.
Takeaway: Overlap remains in the same narrow band (58–65%), with no category approaching full consistency between Google and ChatGPT.
By Prompt Intent
| Prompt Intent | Overlap (Web) | Overlap (No Web) |
|---|---|---|
| General Exploratory | 63% | 62% |
| Feature-Based | 61% | 60% |
| Brand-Seeking | 61% | 61% |
| Total Avg. | 62% | 61% |
Overlap was surprisingly stable across query types:
- Exploratory queries: 63%
- Feature-based decision queries: 61%
- Brand-seeking queries: 61%
Takeaway: Intent type does not materially shift the overlap outcome, visibility gaps persist regardless of how the question is framed.
Browsing ON vs. OFF
Overlap results were nearly identical:
- Browsing ON: 62%
- Browsing OFF: 61%
Takeaway: Real-time browsing access has negligible impact on which brands appear in ChatGPT answers. Visibility is driven primarily by the model’s internal knowledge and semantic associations.
2. Position-to-Position Correlation
This analysis measured whether a brand’s exact position in Google’s top 10 correlated with its order of mention in ChatGPT’s answers.
By Brand
| Brand | Web vs No Web | Google vs ChatGPT (Web) | Google vs ChatGPT (No Web) |
|---|---|---|---|
| Allstate | 0.449 | 0.033 | 0.096 |
| Liberty Mutual | 0.293 | -0.023 | 0.056 |
| Geico | 0.494 | 0.061 | -0.018 |
| Discover | 0.697 | -0.060 | -0.066 |
| Credit Karma | 0.252 | 0.030 | 0.122 |
| Bank of America | 0.327 | 0.037 | 0.024 |
| Expedia | 0.335 | 0.064 | -0.028 |
| Hotwire | 0.467 | -0.165 | -0.122 |
| Kayak | 0.412 | -0.048 | -0.146 |
| Coursera | 0.638 | -0.025 | 0.010 |
| Harvard | 0.414 | 0.300 | 0.080 |
| edX | 0.460 | -0.046 | 0.007 |
| GoDaddy | 0.706 | 0.136 | 0.149 |
| Hostinger | 0.365 | 0.016 | -0.060 |
| Namecheap | 0.637 | 0.194 | 0.228 |
| Total Avg. | 0.463 | 0.034 | 0.022 |
Correlation values were generally very weak, clustered close to zero.
- Slight positive alignment: Harvard (0.30 with web) and Namecheap (0.22 without web) showed some limited consistency in their relative order across platforms.
- Near-zero values: Most brands hovered around zero, indicating virtually no relationship in ordering.
- Negative alignment: Several brands such as Hotwire (-0.16 to -0.12), Kayak (-0.05 to -0.15), and Discover (-0.06 to -0.07) showed inverse correlations, meaning higher placement in Google often did not translate into earlier mentions in ChatGPT.
Takeaway: No brand exhibited strong correlation across platforms. Even the “highest” values represent only weak alignment. Brand rank order in Google has almost no predictive value for ChatGPT ordering.
By Category
| Category | ChatGPT Web vs No Web | Google vs ChatGPT (Web) | Google vs ChatGPT (No Web) |
|---|---|---|---|
| Car Insurance | 0.412 | 0.024 | 0.044 |
| Credit Cards | 0.425 | 0.002 | 0.027 |
| Hotel Booking | 0.405 | -0.050 | -0.099 |
| Online Courses | 0.504 | 0.076 | 0.032 |
| Web Hosting | 0.569 | 0.116 | 0.106 |
| Total Avg. | 0.463 | 0.034 | 0.022 |
Category averages also stayed close to zero:
- Car Insurance: 0.024–0.044
- Credit Cards: 0.002–0.027
- Hotel Booking: -0.050 to -0.099
- Online Courses: 0.076–0.032
- Web Hosting: 0.116–0.106
Takeaway: None of the categories displayed meaningful correlation. Even in cases where individual brands showed the highest positive signals (e.g., Harvard at 0.300 with browsing ON), the broader category average remained weak (Online Courses at just 0.076).
By Prompt Intent
| Prompt Intent | Web vs No Web | Google vs ChatGPT (Web) | Google vs ChatGPT (No Web) |
|---|---|---|---|
| General Exploratory | 0.466 | 0.089 | 0.087 |
| Feature-Based | 0.459 | 0.000 | -0.028 |
| Brand-Seeking | 0.400 | 0.048 | 0.031 |
| Total Avg. | 0.442 | 0.046 | 0.030 |
Breaking results down by query type showed similar patterns:
- Exploratory queries: ~0.08 (the highest of the three, though still weak).
- Feature-based queries: ~0.00 or slightly negative (-0.02).
- Brand-seeking queries: ~0.03–0.04.
Takeaway: Query intent does not materially change the outcome, correlation with Google rankings remains negligible across all prompt types.
Browsing ON vs. OFF
Average correlation between Google rankings and ChatGPT answers was essentially the same in both browsing modes:
- Google vs. ChatGPT (Browsing ON): 0.034
- Google vs. ChatGPT (Browsing OFF): 0.022
By contrast, ChatGPT was much more consistent with itself: ChatGPT Web vs. No Web: 0.463
Takeaway: Browsing mode does not make brand mentions in ChatGPT any more aligned with their rankings in Google.
Conclusions
The results confirm that strong SEO performance in Google does not translate into visibility in ChatGPT answers. While there was some overlap, it was far from consistent:
- Presence vs. Absence: Brands overlapped in only 61–62% of cases across platforms, meaning nearly 4 out of 10 times Google and ChatGPT diverged on whether a brand appeared at all.
- Position Correlation: Rank order alignment was even weaker, with correlations near zero (0.034 with browsing ON, 0.022 with browsing OFF). Being #1 in Google does not predict being first in ChatGPT.
- Stability check: ChatGPT was far more consistent with itself (0.463 between browsing modes) than with Google.
- Across all dimensions tested (brand, category, query intent, browsing mode), no scenario produced strong alignment.
While there are overlapping practices between SEO and GEO, strong SEO alone is not enough to secure visibility in ChatGPT.
Disclaimer
This study represents a controlled experiment on a defined dataset of five categories, fifteen brands, and 1,000 overlapping queries. Our goal was not to capture every possible user interaction with Google or ChatGPT, but to create a structured “apples-to-apples” environment that makes the two platforms comparable at a macro level.
Several important points to note:
- Sample scope: Results reflect this specific dataset. Expanding to more categories, brands, or query types may yield different outcomes.
- Simulated prompts: Unlike Google, where keyword data is explicit, prompts in ChatGPT are unknowable in advance. We therefore converted known Google queries into natural-language prompts designed to approximate real user phrasing. This is not a perfect reflection of all possible prompts, but it is the cleanest method available without violating platform terms of use (via API rather than UI scraping).
- Persona effects: In real-world use, ChatGPT may adapt answers based on the identity and context of the user. To reflect this, our study used persona-based prompting, where each query was asked “on behalf” of a defined U.S. persona with a clear backstory (e.g., a 19-year-old student, a frequent business traveler etc.). This approach allowed us to simulate realistic user interactions in a consistent, repeatable way. At the same time, it is important to note that personas are necessarily simplified and cannot capture the full diversity of real-world users.
- Methodological limits: No study of this kind can fully eliminate differences between search engines (which rank URLs) and LLMs (which generate answers probabilistically based on semantic patterns.). This research measures overlap and correlation under a controlled framework, not absolute truth.
- Consistency check: To validate, we ran the study twice: once on GPT-3 and again on GPT-5. Both produced nearly identical results, giving us confidence that the findings are stable across model versions.
The results should therefore be read as directional evidence: a structured snapshot of whether SEO practices that drive visibility on Google also influence visibility on ChatGPT (where they align and where they don’t) under carefully controlled conditions, rather than a universal law of search behavior.